AMD 发布 CDNA 4 架构: HBM3E 加持, 聚焦提升 AI 负载能力
- 2025-06-27 01:47:30
- 262
IT之家6月19日消息,科技媒体chipsandcheese昨日(6月18日)发布博文,报道称AMD正式发布CDNA4架构,在保持在通用向量运算领域的优势外,主要聚焦提升低精度数据类型的矩阵乘法性能,以强化人工智能(AI)工作负载处理能力。
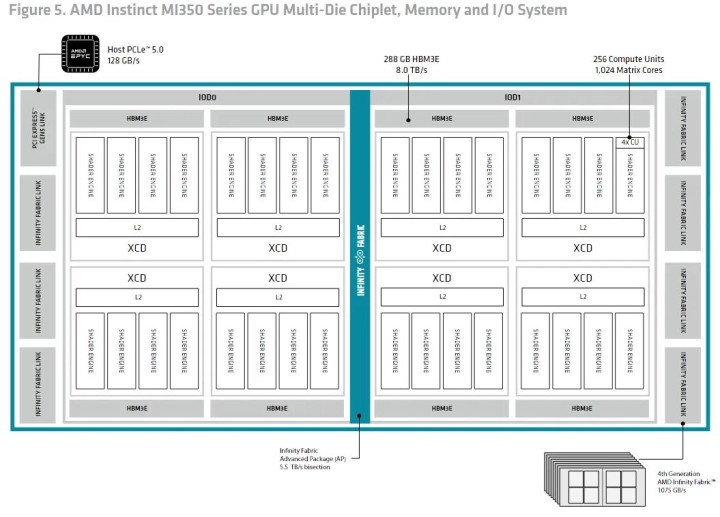
CDNA4延续了CDNA3的模块化设计,采用类似CPU的芯粒(chiplet)布局。每个计算芯片单元(XCD)搭载CDNA计算单元(CU),通过四块基底芯片整合八块XCD,形成包含256MB内存侧缓存的完整GPU架构。
与CDNA3的MI300X相比,CDNA4的MI355X通过减少单XCD的CU数量并关闭部分单元以提升良率,但凭借更高时钟频率缩小了性能差距。
在低精度矩阵运算这个AI关键指标中,CDNA4的每CU矩阵吞吐量翻倍,其FP6精度性能与英伟达B200的流式多处理器(SM)持平。
但在8位与16位数据类型中,英伟达仍保持单周期吞吐量优势。然而,AMD凭借更高的CU数量与频率,维持了通用向量运算(如FP32)的绝对领先,单CU仍提供128条FP32运算管线,整体性能远超英伟达Blackwell架构。
CDNA4的核心改进之一是提升本地数据共享(LDS)的容量与带宽。LDS容量从64KB增至160KB,读取带宽翻倍至每周期256字节,并新增“转置读取”指令,优化矩阵乘法的内存访问效率。
尽管英伟达的共享内存(SharedMemory)在单核容量与缓存灵活性上更优(最高228KB可分配为共享内存或L1缓存),但AMD通过40MB全GPULDS容量(B200仅约33MB)弥补了核心级存储的不足。
显存方面,MI355X升级至HBM3E技术,总带宽达8TB/s,容量288GB,显著超越英伟达B200的7.7TB/s与180GB。这一优势在大数据量运算中尤为重要,尤其当AI模型超出显存容量时,AMD的架构可减少数据交换延迟。
该媒体认为AMD的CDNA4延续了CDNA3的“保守进化”路线,类似Zen3到Zen4的迭代逻辑,通过优化而非颠覆性创新巩固优势。其策略聚焦于扩大计算规模与显存带宽,同时针对性补足AI短板。
该媒体认为在提升性能方面,AMD和英伟达的路径差异显著:AMD依赖“大芯片+大缓存”模式,而英伟达更注重显存带宽与单核效率。
- 上一篇:原来榫卯也能当游戏通关密语
- 下一篇:山东历史
